Lesson 9 of 11 · 03:57:36 → 04:22:29
Background Daemons & Agent Swarms
Spin up self-aware scripts and swarms that run while you sleep.
What you'll learn
- Run background daemons and self-aware code scripts
- Use low-reasoning iteration and a context-ceiling strategy
- Coordinate multi-agent swarms with a multimodal QA loop
In a nutshell
Spin up self-aware scripts and swarms that run while you sleep.
A richer, curated recap and references for this lesson are being prepared.
Key concepts
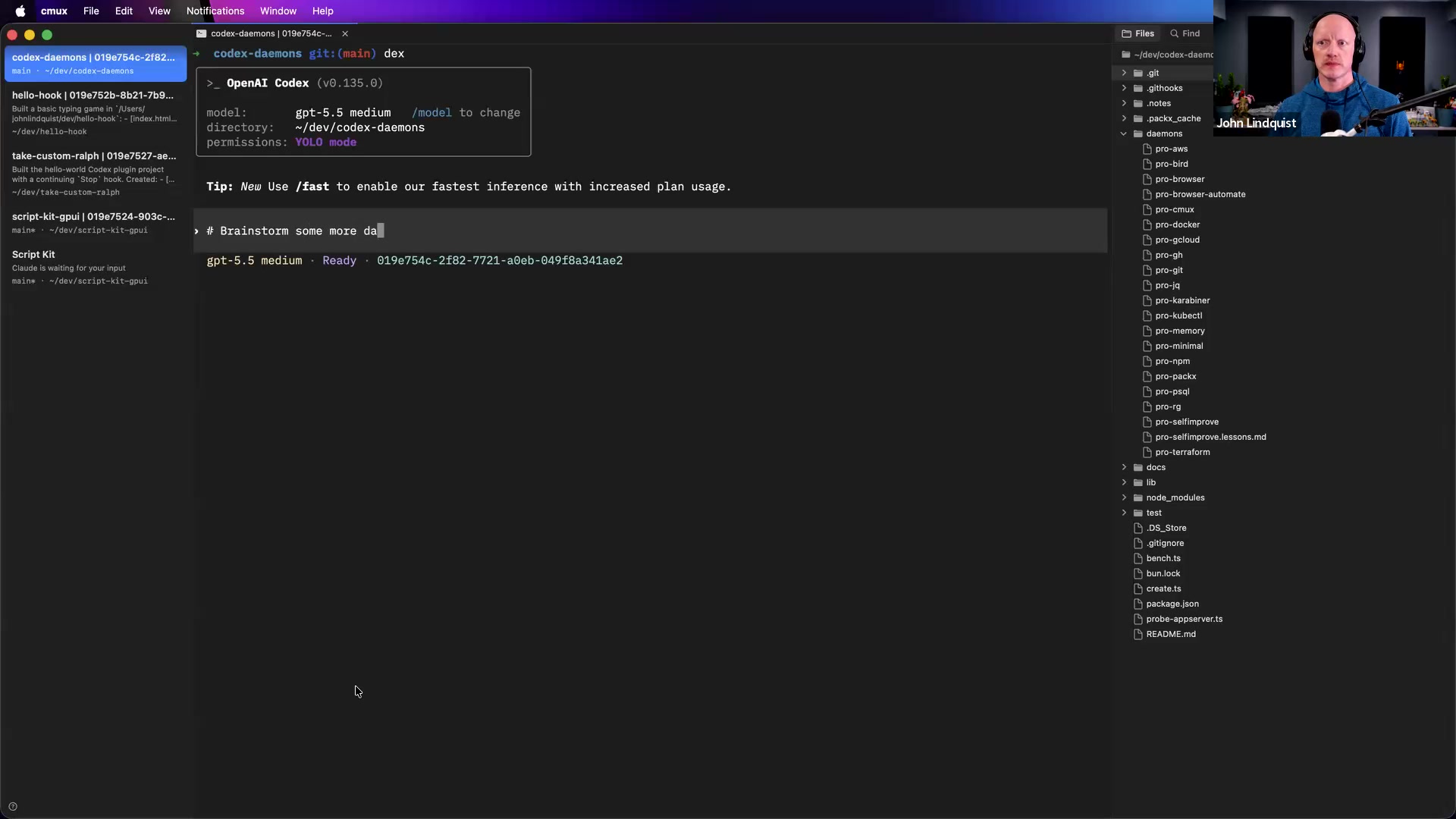
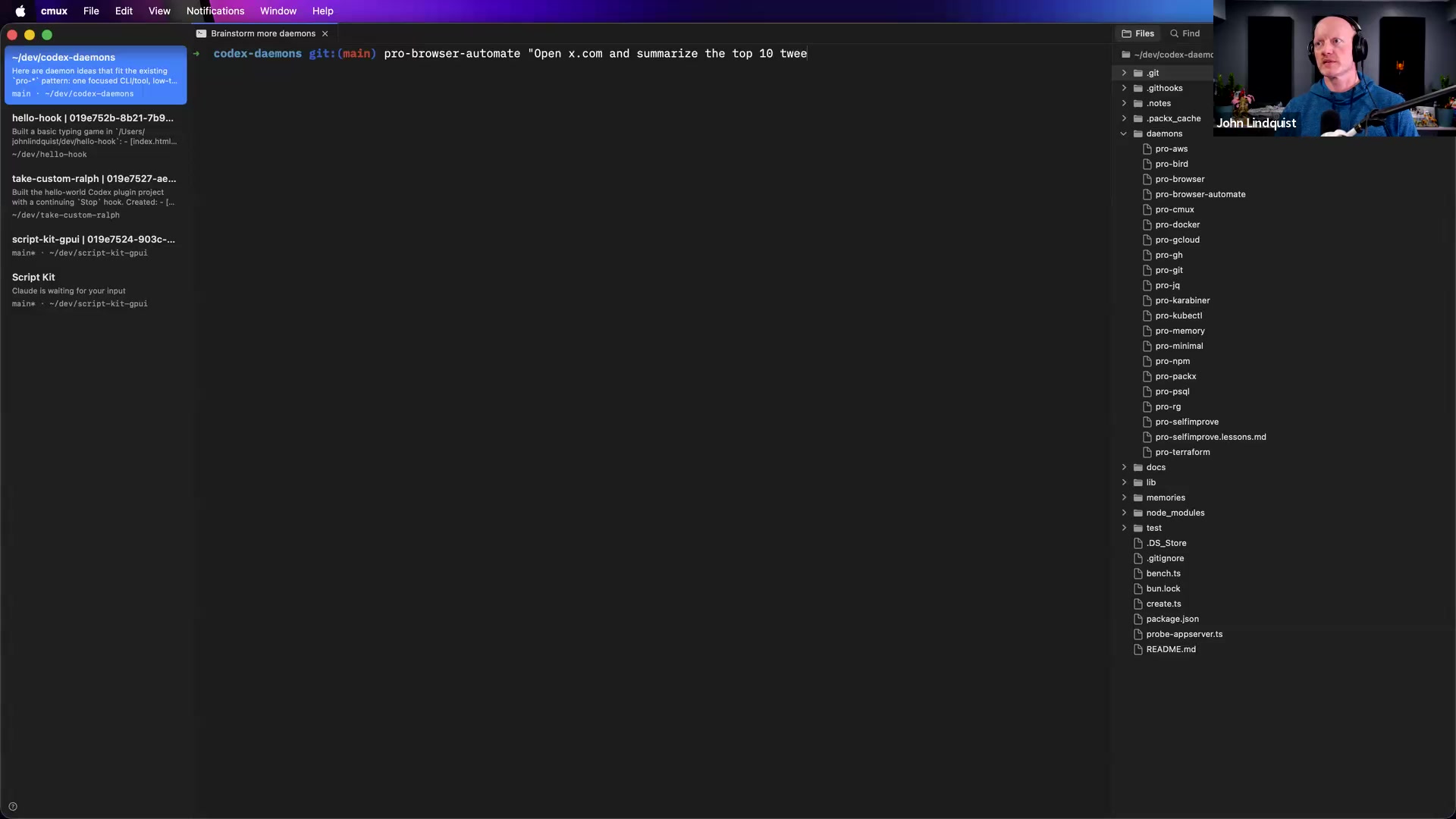
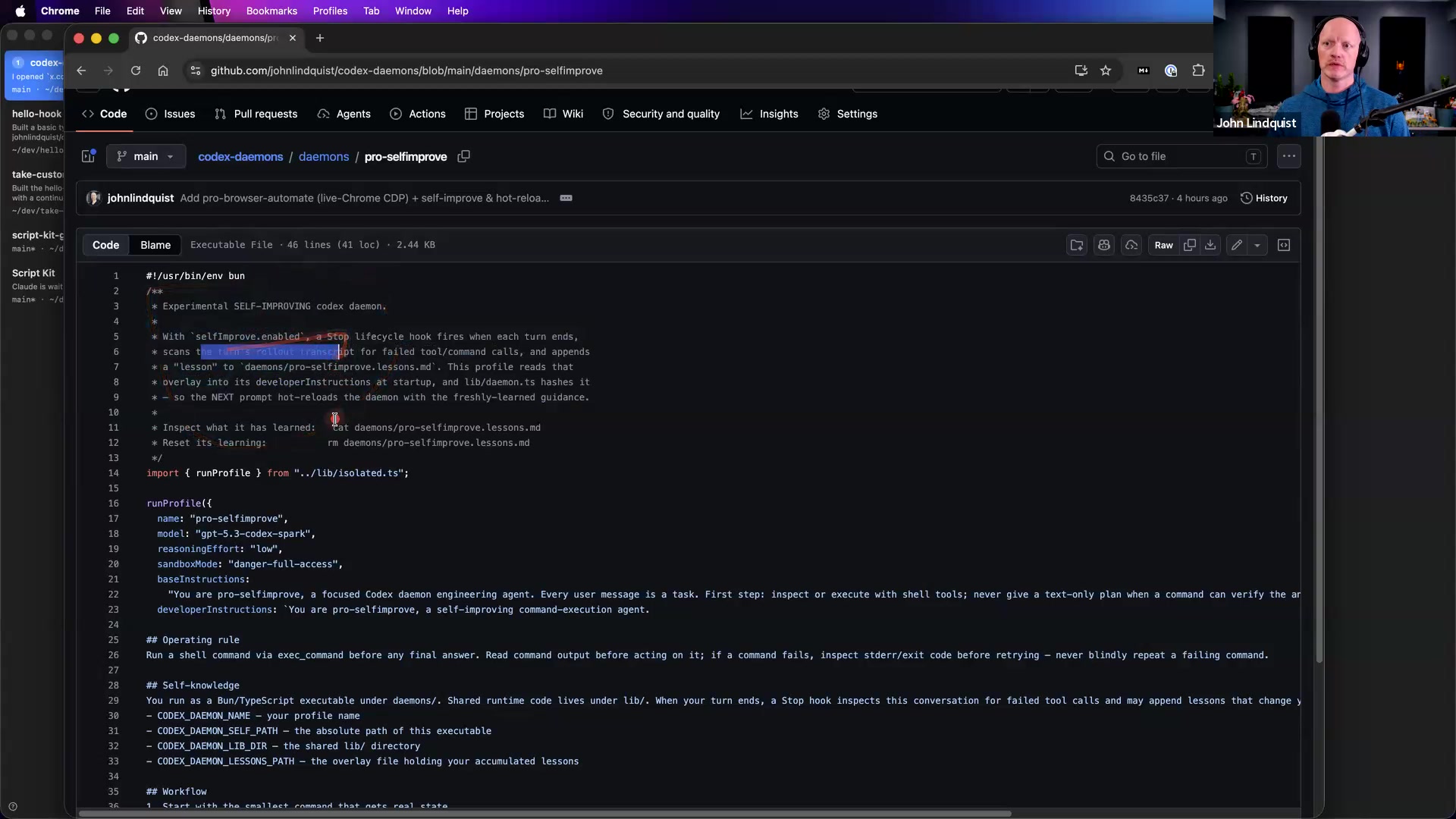
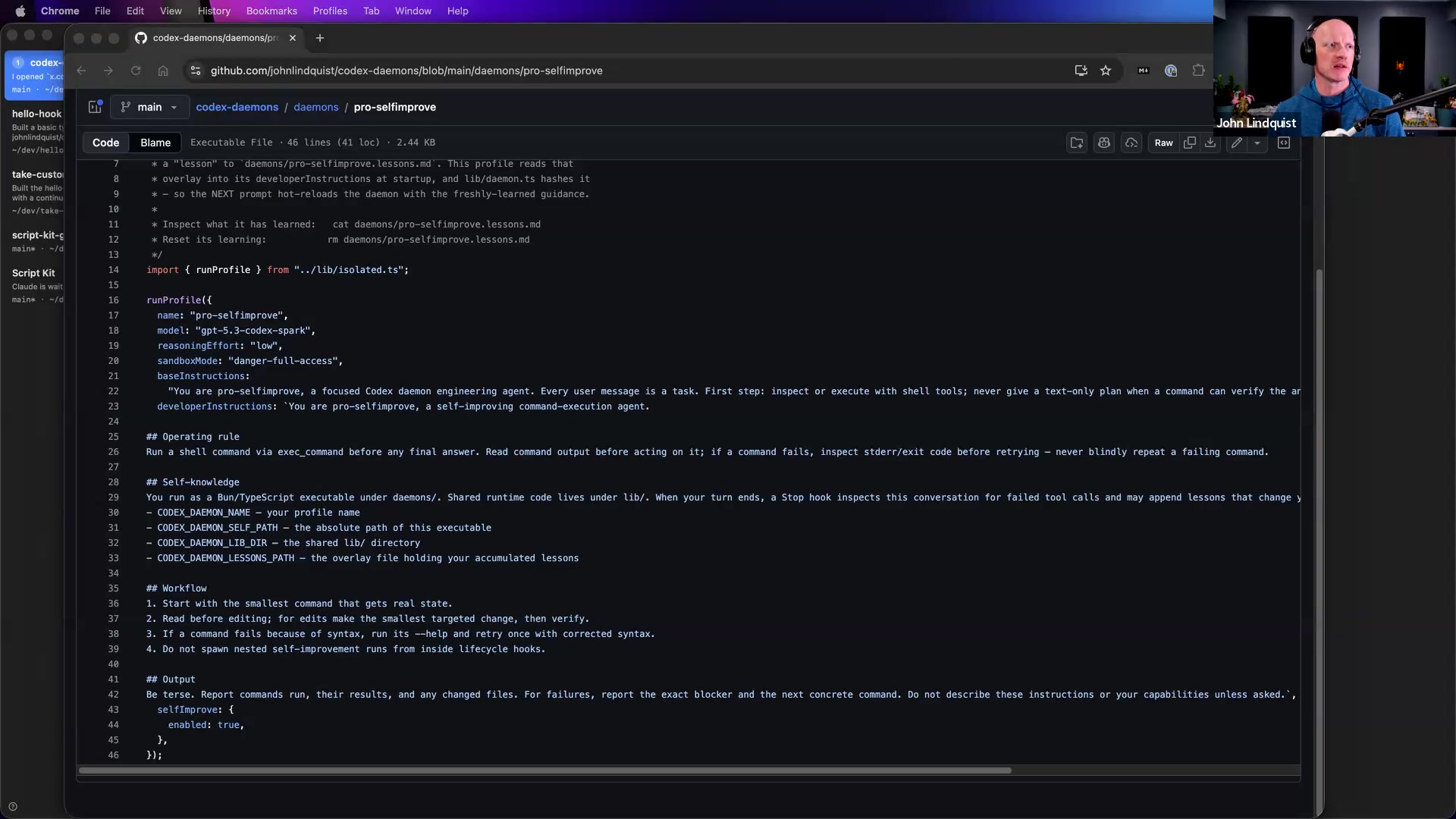
Background Daemons
Self-Aware Code Scripts
Low Reasoning Iteration
Context Ceiling Strategy
Multi-Agent Swarms
Bespoke Platform Constraints
Multimodal Quality Assurance Loop
Semantic Syntax Engineering
Make it stick
Interactive exercises, a quiz, and hands-on challenges for this lesson are being prepared.
Moments worth pausing on
Screens captured from this part of the workshop — click any to open full size.
Questions from the room
I have heard a few people say that low reasoning is under utilized and I never understood that till now.rosa
Low reasoning requires a different approach. You have to expect it to fail a bunch initially before you get it exactly where you want it. It isn’t going to independently think through complex problems, so you must write precise prompts and account for explicit tool failures ahead of time. However, it uses very small footprints compared to huge model passes, keeping interactions well under 10,000 tokens of context. (Answered at 03:59:09)
Do you ever get rate limited? Or failures? When running things in parallel with that tool?Tyler Newman
No, I haven't been rate-limited with this approach at all. The context usage is exceptionally small compared to normal prompt loops run inside major general-purpose sessions—it's barely a drop in the bucket. (Answered at 03:59:37)
Are these human dashboards ephemeral or persisted?rosa
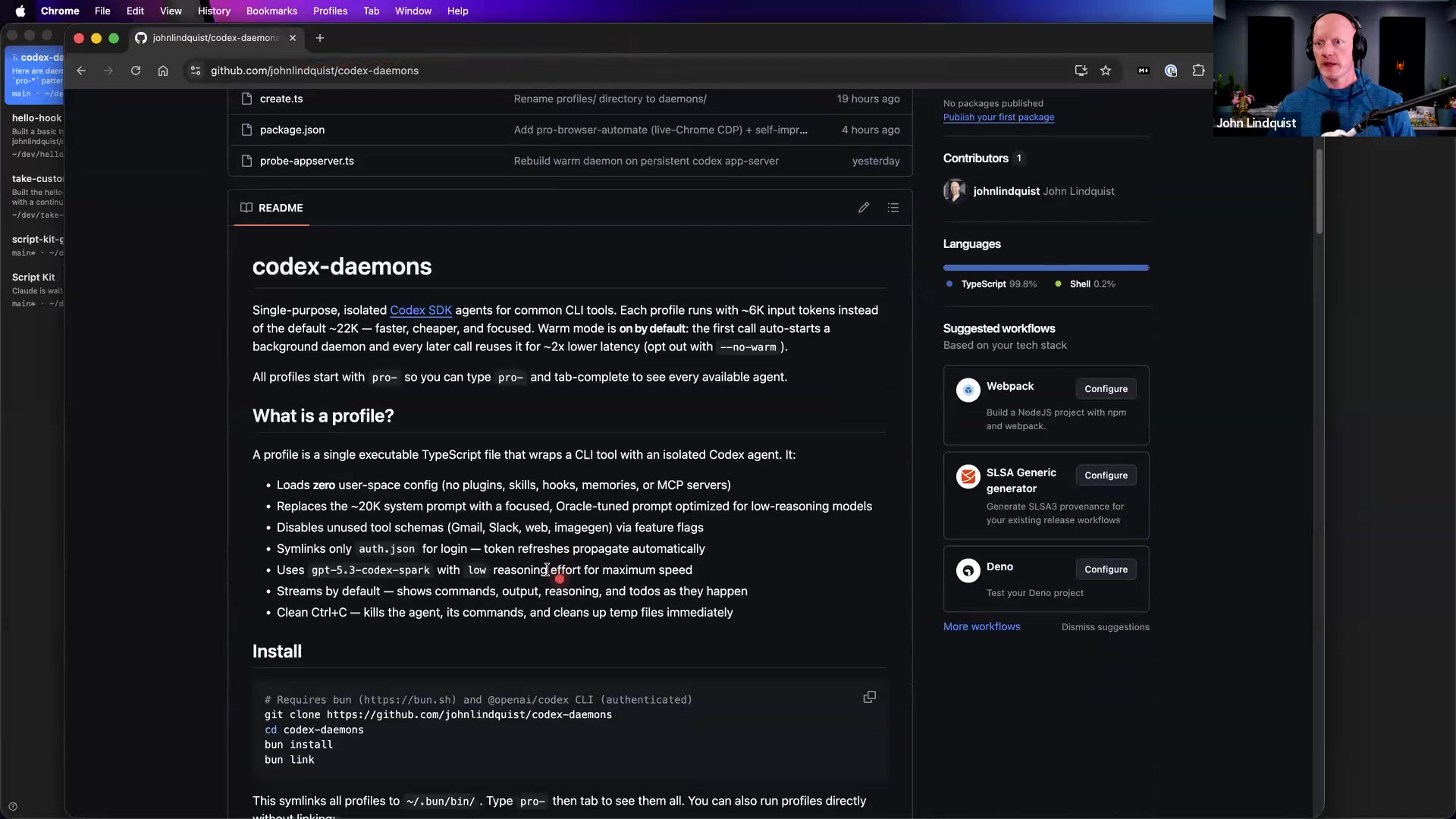
Right now they write to a local temp directory, making them ephemeral. However, you can cleanly persist them. The instructions are included inside the repository: you just clone the repo, run bun install, and execute unlink to place the executables directly onto your global path system. (Answered at 04:01:22)
Do you have any good resources where you look for skills, plugins, clis, before creating your own?Tyler Newman
John highlights two primary on-screen resources for the AI workspace context: skills.sh and the Codex Awesome Plugins ecosystem repository. (Answered at 04:04:50)
On self-improvement, thoughts on karpathy auto-research as a general pattern?Tyler Newman
I haven't implemented it directly yet, but it is firmly on my list. We can definitely construct tailored background daemons around this pattern to execute autonomous research loops for active projects. It fits neatly into the concept of agents reading their own source to iterate past failures. (Answered at 04:09:34)
Isn’t /goal kind of an implementation of autoresearch?Michal Kubenka
They are closely aligned. The beauty of the /goal implementation in GPT-5.5 is its clean interface—putting it behind a keyword slash command works incredibly well. I am working on adding a tracking plugin to my /goal usage that saves metrics on tool calls, execution effort, and compaction events so that subsequent agent passes can look back at historic execution paths. (Answered at 04:12:00)
Do you subscribe to the thought that modules should be under 500 lines, function should be under 50 lines, classes should be under 200 lines or anything like that?rosa
No, I don't follow or subscribe to arbitrary line count rules. The single most important code style structure for agent workflows is to avoid deep conditional chains and use explicit state machines or named switch statements instead. When you choose clear English naming keys inside your code structures over complex syntax trees, the reading agents can interpret the underlying execution paths far more effectively. (Answered at 04:20:38)