Lesson 4 of 11 · 01:20:25 → 01:38:20
Source of Truth Over Stale Memory
Trust the code, snapshot a million tokens, and capture design in design.md.
What you'll learn
- Tell the difference between basic memory and dangerous stale memory
- Treat code as the source of truth with million-token snapshot contexts
- Capture a design.md standard and generate multi-route structural variants
In a nutshell
Trust the code, snapshot a million tokens, and capture design in design.md.
A richer, curated recap and references for this lesson are being prepared.
Key concepts
Basic Memory vs. Stale Memory
Source-of-Truth Code
Million-Token Snapshot Contexts
YOLO Bypassing (Sandbox Approvals)
Design.md File Standard
Multi-Route Structural Variants
Make it stick
Interactive exercises, a quiz, and hands-on challenges for this lesson are being prepared.
Moments worth pausing on
Screens captured from this part of the workshop — click any to open full size.
Questions from the room
Are you using the memory features of these harneses? I noticed they get out of date when I use them and shifted to beads but even that has some clunk still https://github.com/gastownhall/beadsunknown
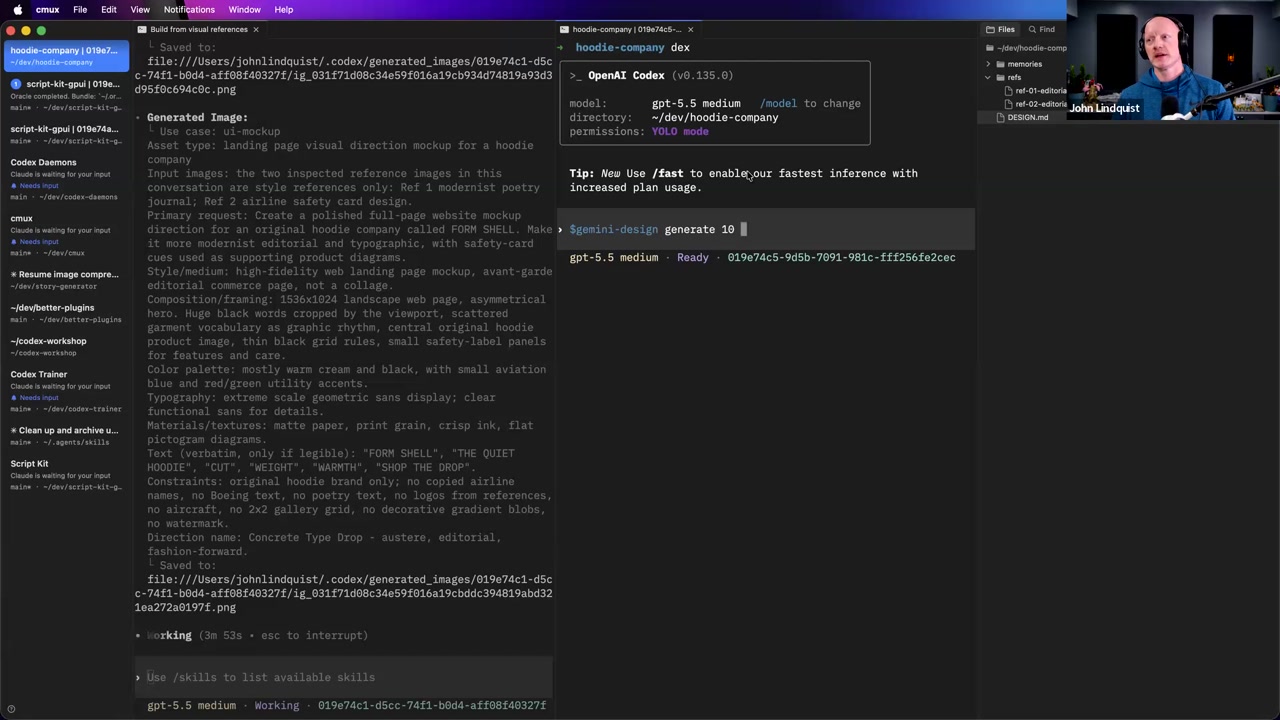
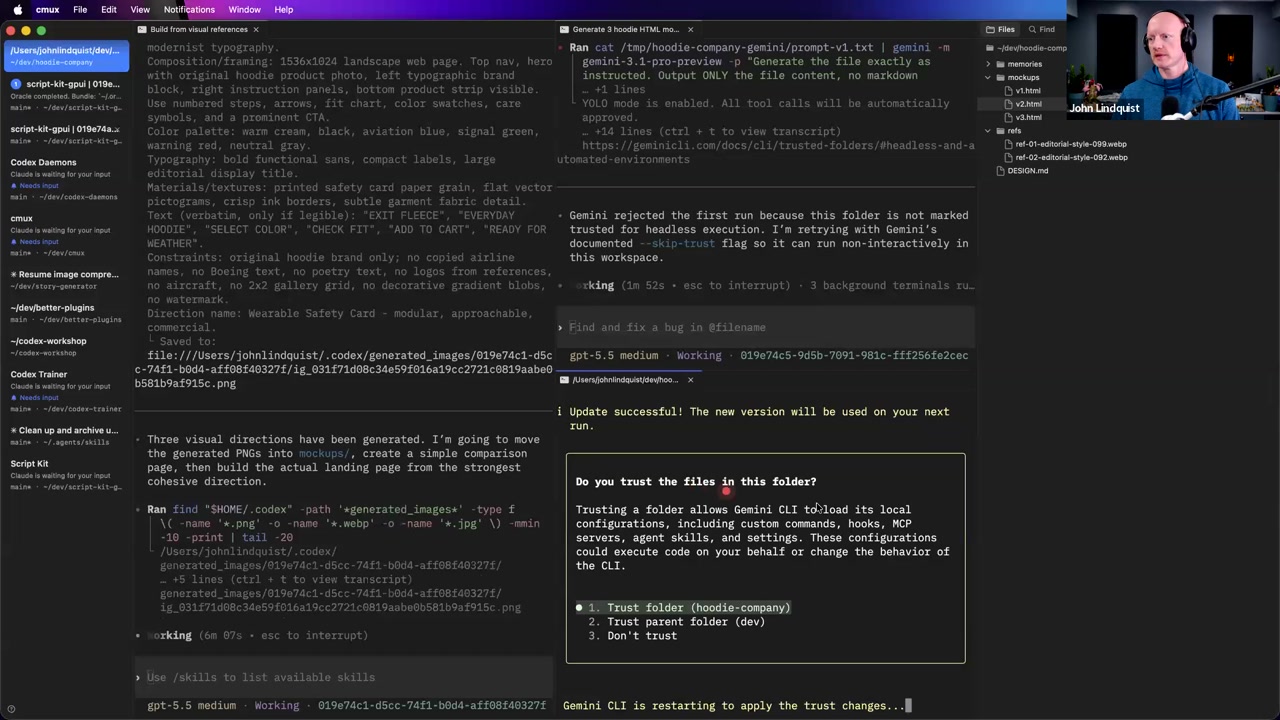
Memory systems frequently run out of date because the underlying codebase is the ultimate source of truth. Attempting to continuously update external memory stores on every commit quickly turns into an administrative bottleneck. John suggests keeping project memories as lightweight as possible. He also mentions an alternative: leveraging large context allowances (like Oracle's 1 million token limit) to pass raw codebase snapshots directly into the context window, bypassing the need for explicit memory stores.
I use basic memory that i got from you a while back, I still find it to be an excellent tool, I like to use it to keep things documented for developers within the same repository, would love to know if you still use it, and for what purpose, I know karpathy popularized simple, obsidian graph knowledge as opposed to a rag vector retrieval, basic memory seems to have best of both worldsunknown
John agrees that basic memory approaches that rely on simple Markdown file formatting combined with straightforward RAG mechanisms work well because they avoid unnecessary over-engineering. He notes that unless an advanced automated context synchronization system emerges, keeping documentation minimal and close to the raw source files remains the most practical path forward.
Were you ever a fan of warp terminal? This cmux looks like I might be able to get rid of that subscription!unknown
John used Warp for a short period but eventually ran into specific workflow limitations. Certain built-in keyboard shortcuts and essential macro behaviors were unsupported at the time, leading him to return to terminal workflows like `cmux`. He notes that Warp has since moved open-source, and mentions he would gladly return to any terminal harness layer if it becomes highly agentic, performant, and serves his user experience goals better.
This is a little off topic but when generating a lot of research what guiding principles do you reach for to staying organized as well as optimize for the ai’s retrieval ?unknown
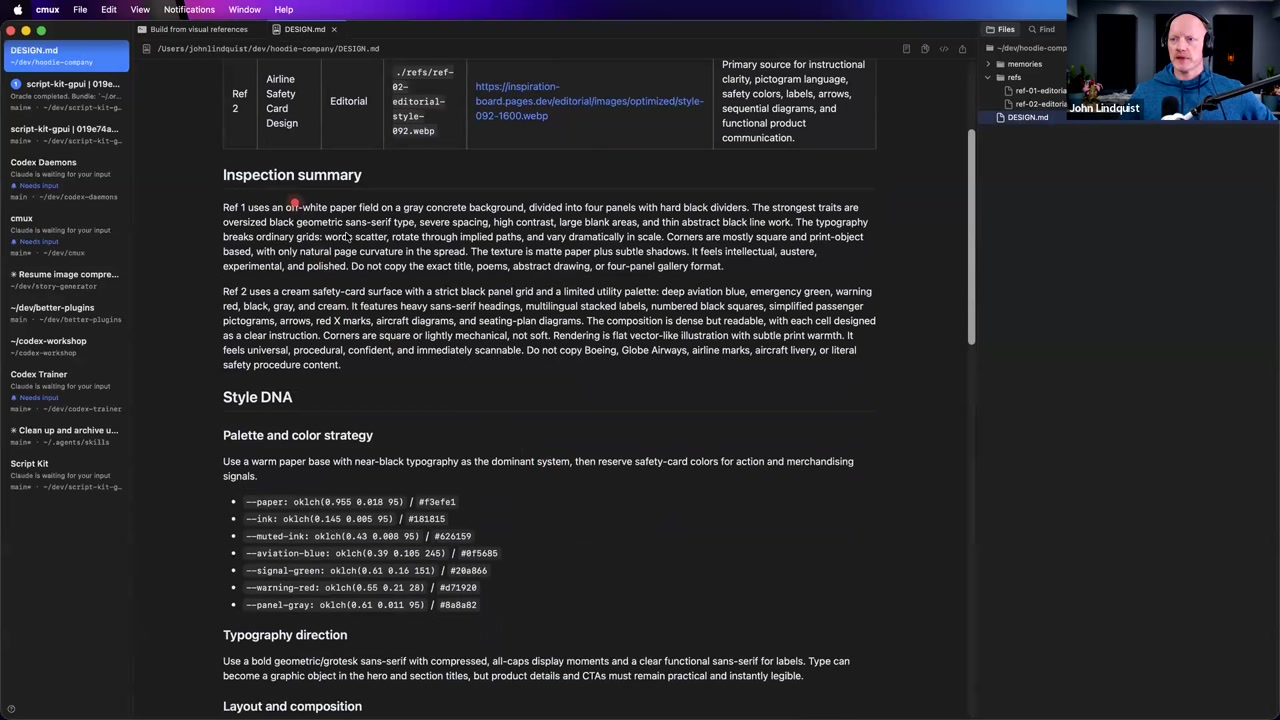
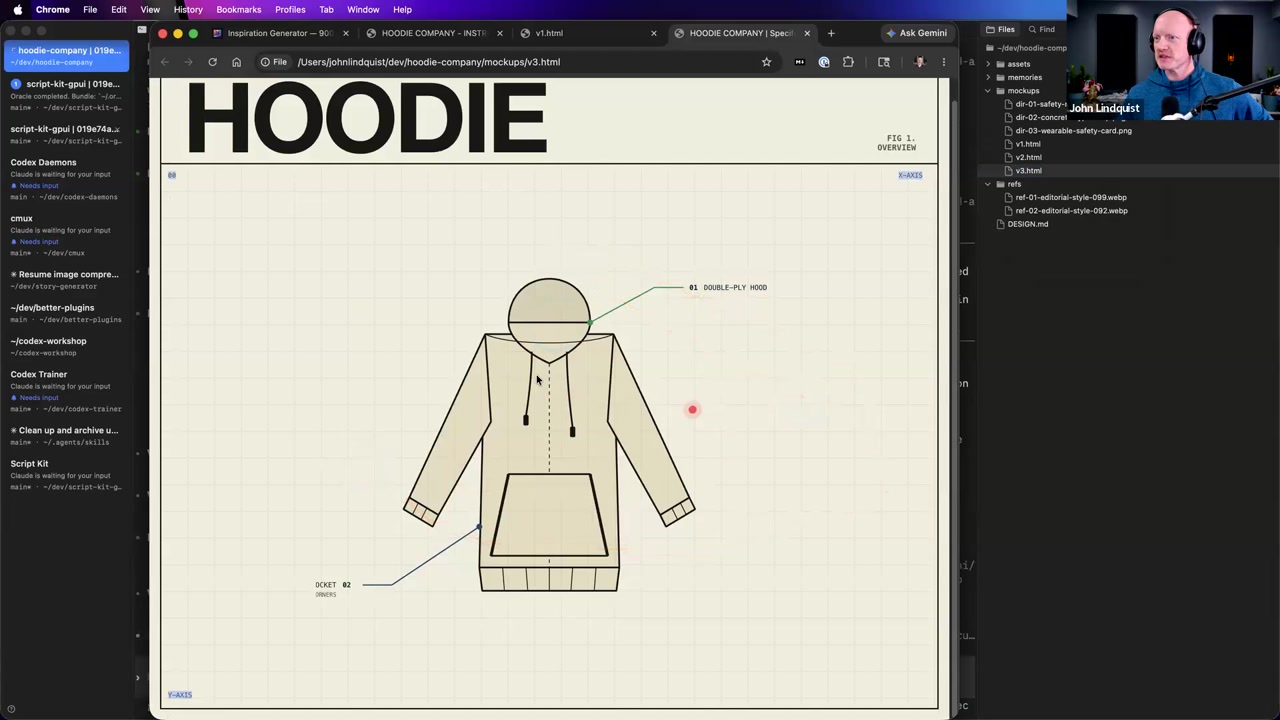
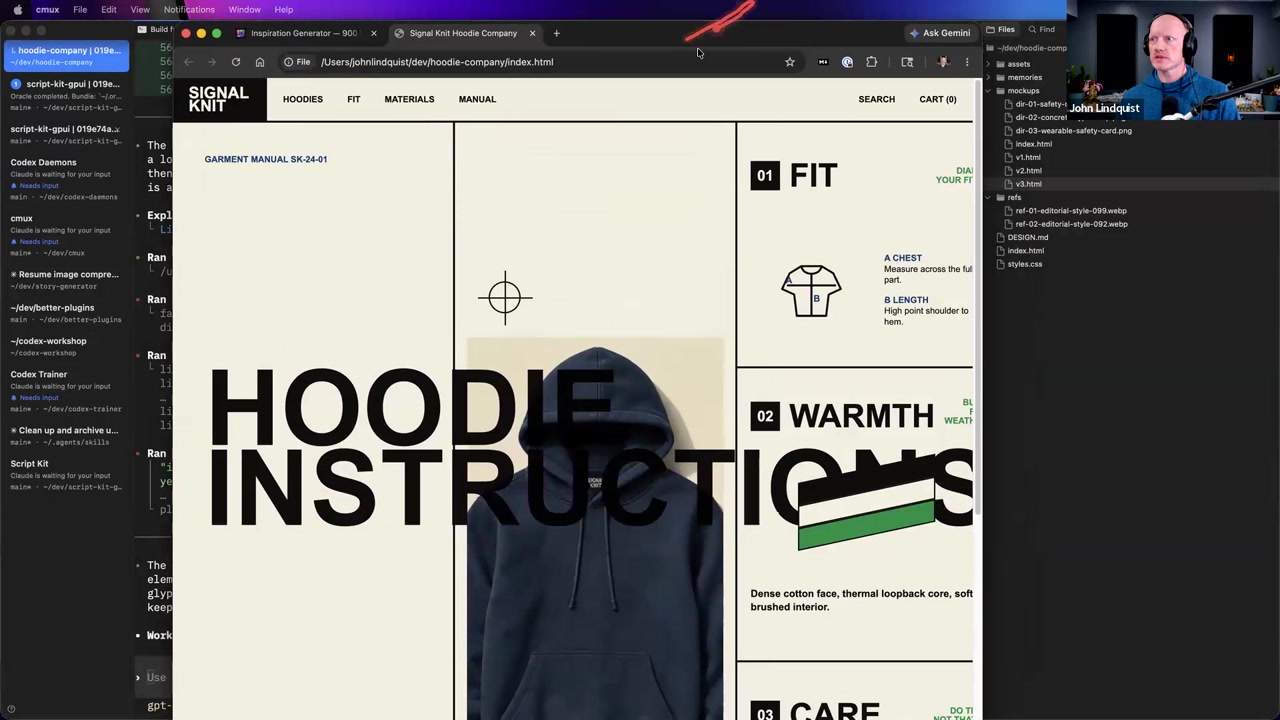
Note: The transcript slice for this chunk cuts off right as John is wrapping up the hoodie layout visualization demo. The detailed structural breakdown for research data ingestion and multi-perspective QA workflows takes place immediately within the following workshop section (detailed in Next Chunk Preview).